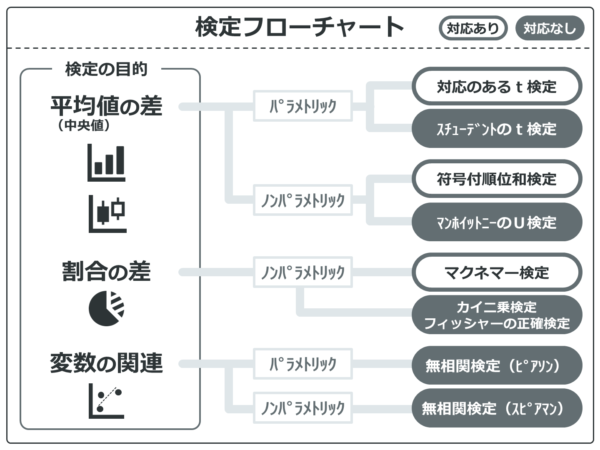
この記事ではソザイヤサンで使うEZRのデータセットの説明と配布を行います。
データセットの読み込み方法
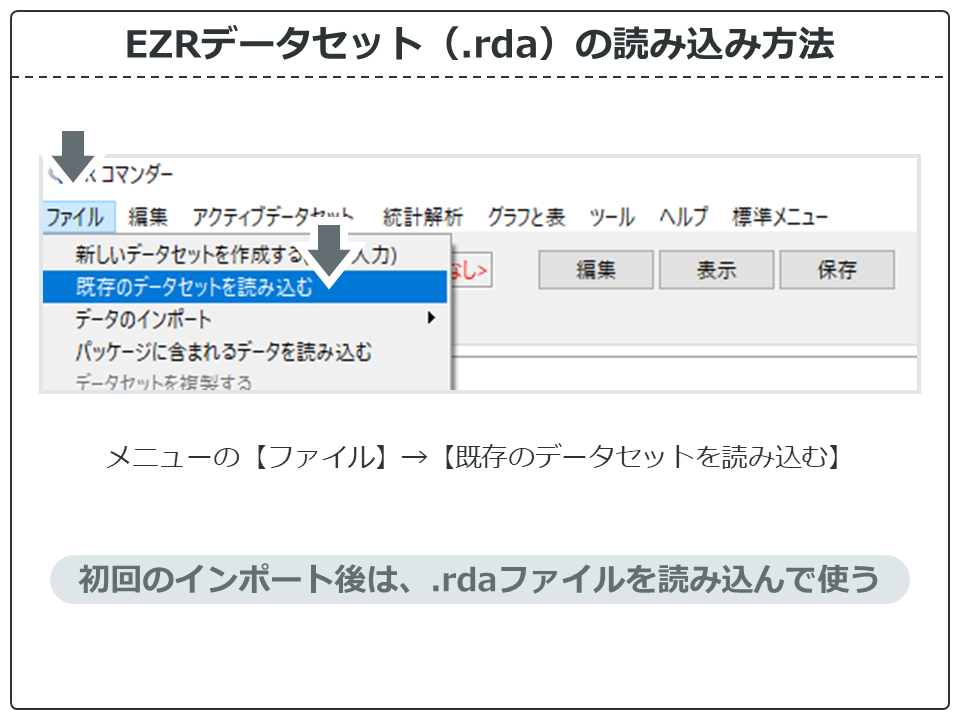
EZR用データセット(.rdaファイル)は、【ファイル → 既存のデータセットを読み込む】から読み込むことができます。そのほか、Excel等からインポートする方法もあります。詳しくは関連記事を参照してください。

EZR基本解析用のデータセット
基本解析用のデータセットです。このデータセットは、基本的な二群間の比較検定の練習ができるようになっています。
EZRの最新バージョンの文字コード(UTF8)に対応しました。
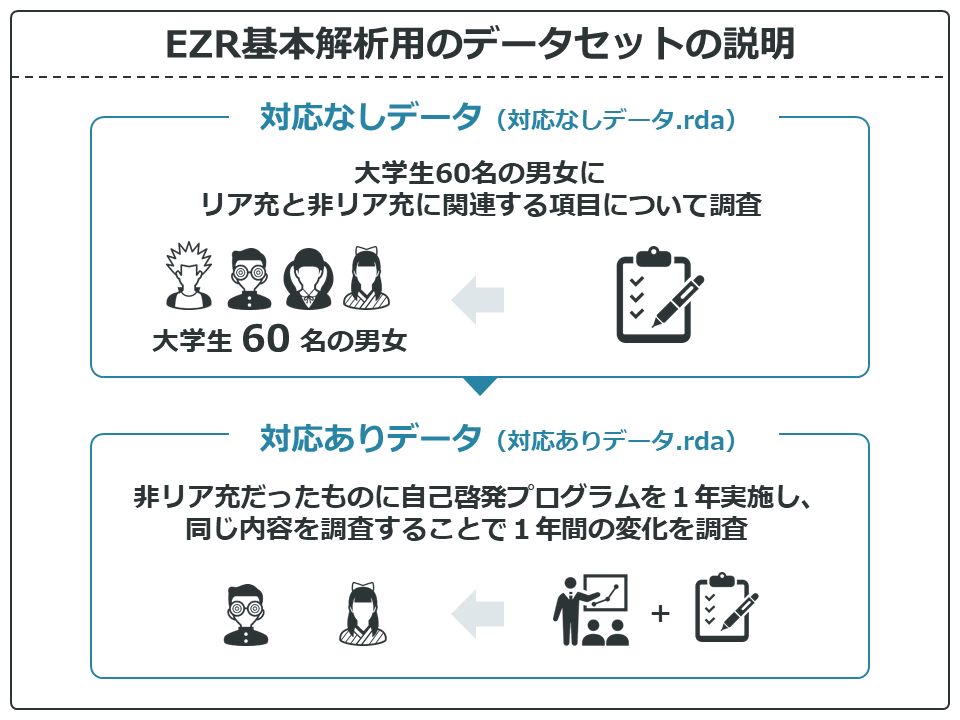
対応なしデータは大学生60名の男女に、リア充と非リア充に関する項目について調査したデータセットです。
対応ありデータは、ベースラインで非リア充だったもの30名に対して1年間の自己啓発プログラムを実施した結果をまとめたデータセットです。

変数の一覧です。IDから8種類の変数があります。
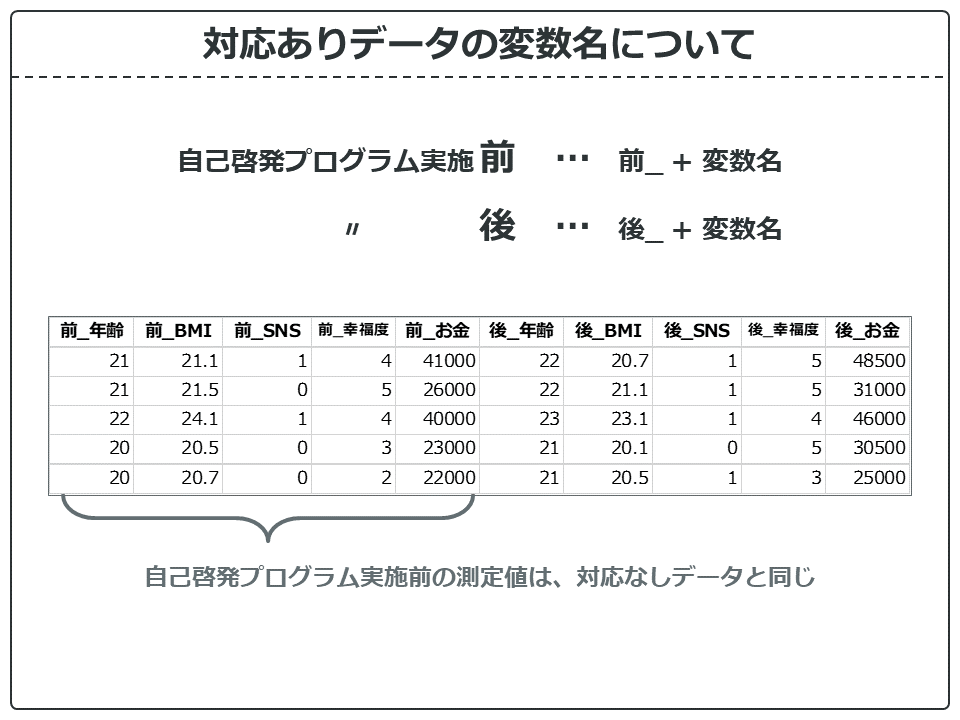
対応ありデータには変数名の前に「前_」「後_」がついています。自己啓発プログラムの前後どちらで測定したデータかがわかるようになっています。
EZR高度解析用のデータセット
高度解析用のデータセットです。このデータセットでは、三群以上の比較検定や多重比較検定、トレンド検定、回帰モデルの練習ができるようになっています。
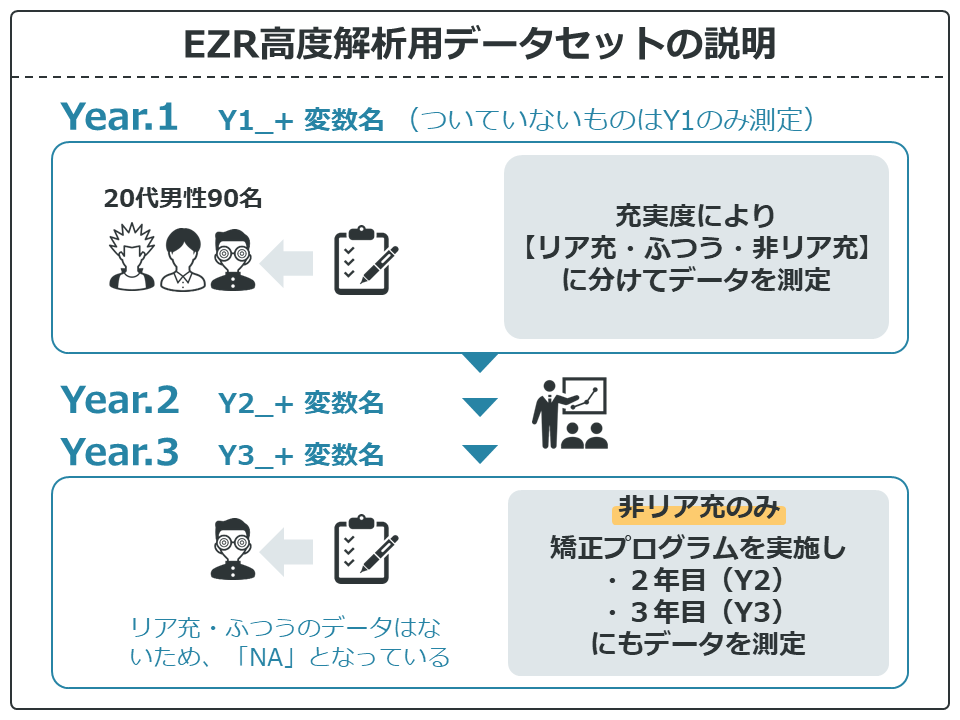
20代男性90名を対象に、充実度に関して調査したデータです(架空データ)。
充実度により【リア充・ふつう・非リア充】に分けてデータを測定しています。
また、1年目(Year1)で【非リア充】に分類された人には、強制プログラムを2年間受けてもらっています。どんな内容かはご想像にお任せします。
データは1年目(Year1:Y1)および非リア充のみ2年目(Year2:Y2)および3年目(Year3:Y3)を測定しました。変数名の冒頭の記号で、いつ測定したかわかるようになっています(例 Y1_身長)。冒頭に記号がない場合は1年目のみ測定しています。
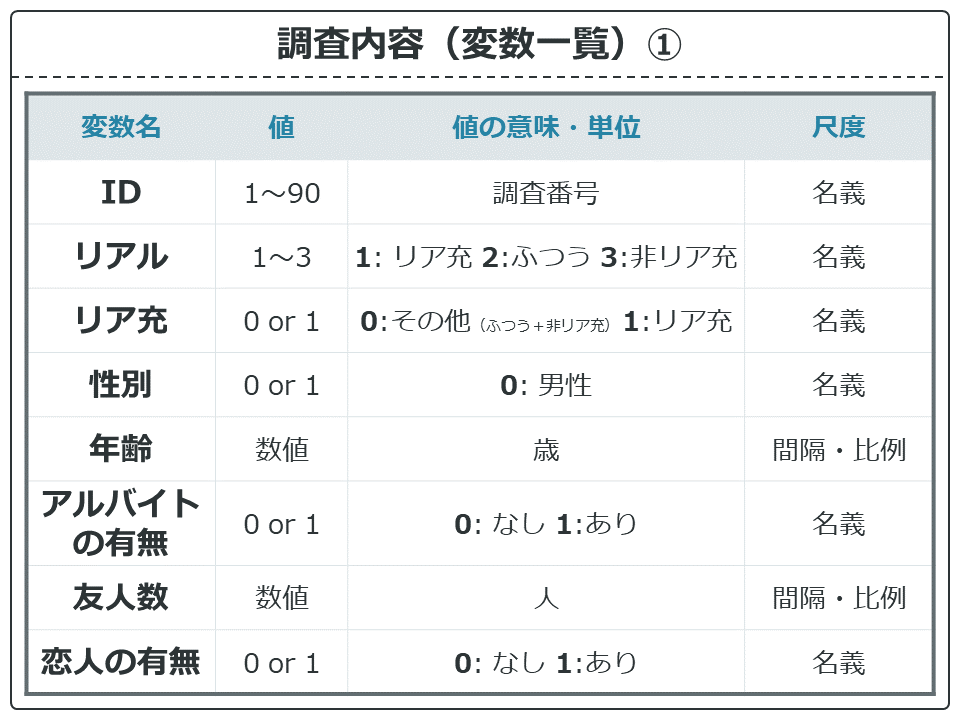
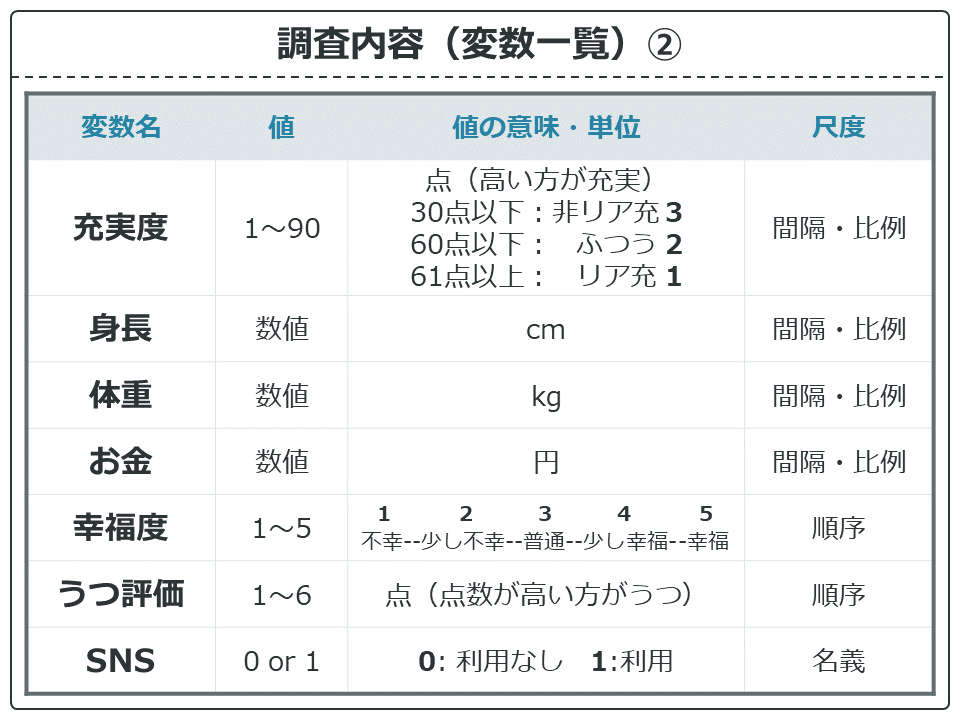
変数一覧です。IDから15種類の変数があります。Year2、Year3に関しては非リア充のみのデータで、他は欠損値(NA)となっています。
その他のデータセット
新しいデータセットがあれば、こちらに追加していきます