この記事では、統計×デザインのソザイヤサン(本サイト)が作ったExcelのみで簡単な統計ができる”E統計”を使って統計の勉強をします。計算式や関数がわからなくても大丈夫です!※論文投稿では使えません(あくまでExcelでやる統計の練習用です)
ダウンロードしていない方は、下記からE統計とデータをダウンロードしてください
それぞれの説明が必要な場合は下記からどうぞ

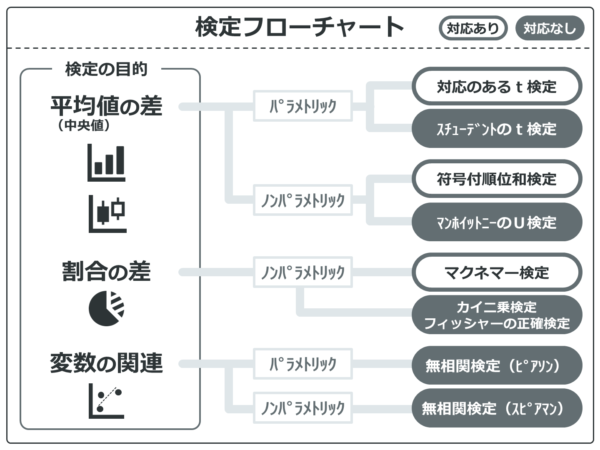
エクセル(E統計)でやるカイ二乗検定
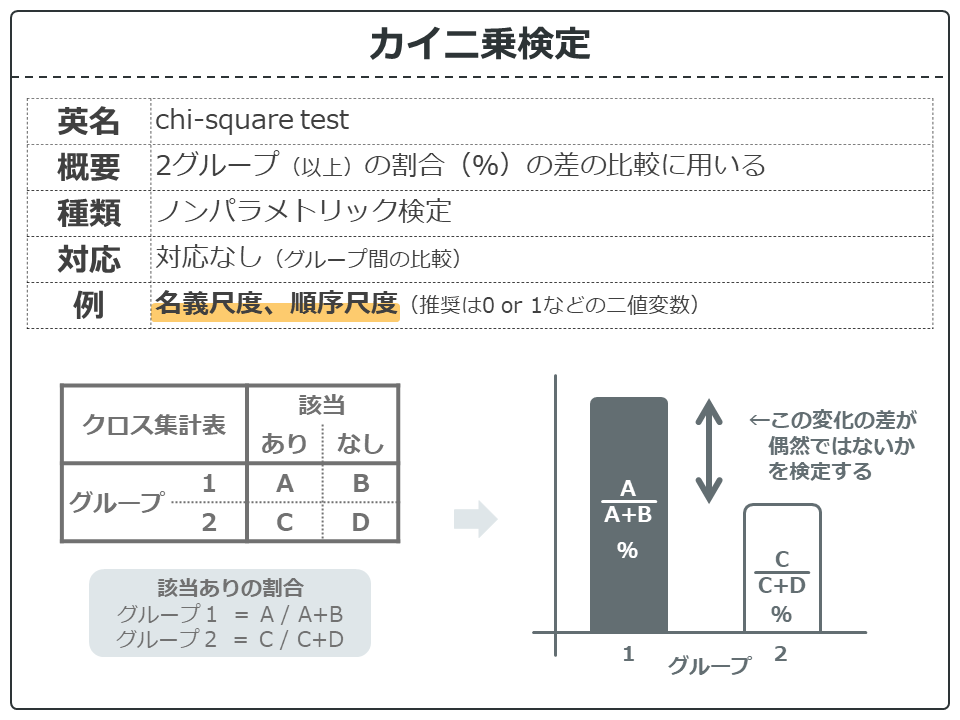
検定手法の概要です。カイ二乗検定は対応のない割合の差の検定を行うノンパラメトリック検定です。
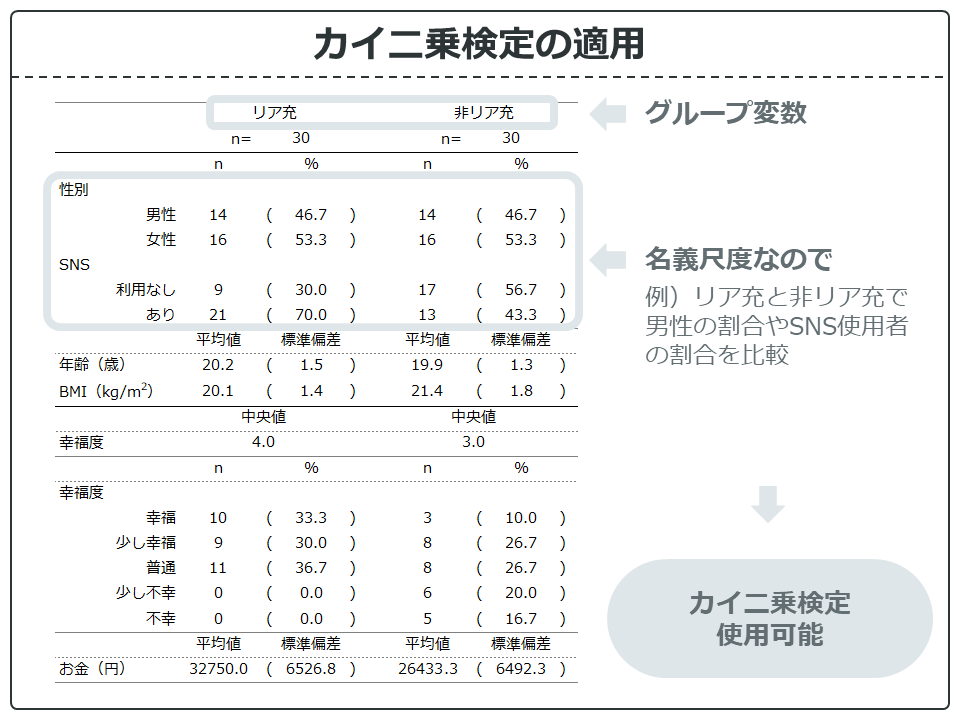
では、「対応なしデータ」の基本統計量の表を見ながら、どこにカイ二乗検定が適用できるか確認していきましょう。
カイ二乗検定はグループ変数ごとに名義尺度や順序尺度の該当割合を計算します。
「対応なしデータ」の場合、「性別」(男性の割合または女性の割合)や「SNS」(利用者の割合や非利用者の割合)の割合の差はカイ二乗検定で検定できます。
また、幸福度についても検定できないこともないですが、リアル×幸福度だと2×5のクロス集計表になってしまうので結果の解釈が難しくなるのでおすすめできません(E統計では計算不可)
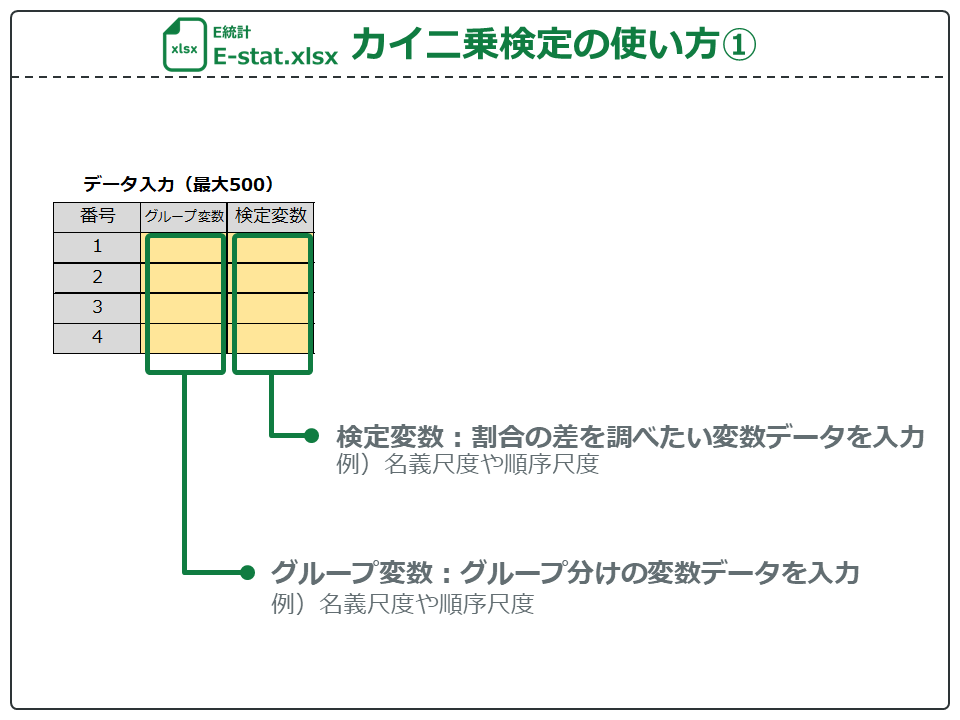
E統計のカイ二乗検定の使い方です。
グループ変数にはグループ分けの変数のデータを入力します。「対応なしデータ」の場合、リアルや性別の名義尺度が入ります。また、幸福度の順序尺度を入力して、不幸グループと幸福グループで検定することもできます。
検定変数には、差を調べたい変数のデータを入力します。「対応なしデータ」の場合、性別やSNSなどの名義尺度を入力します。
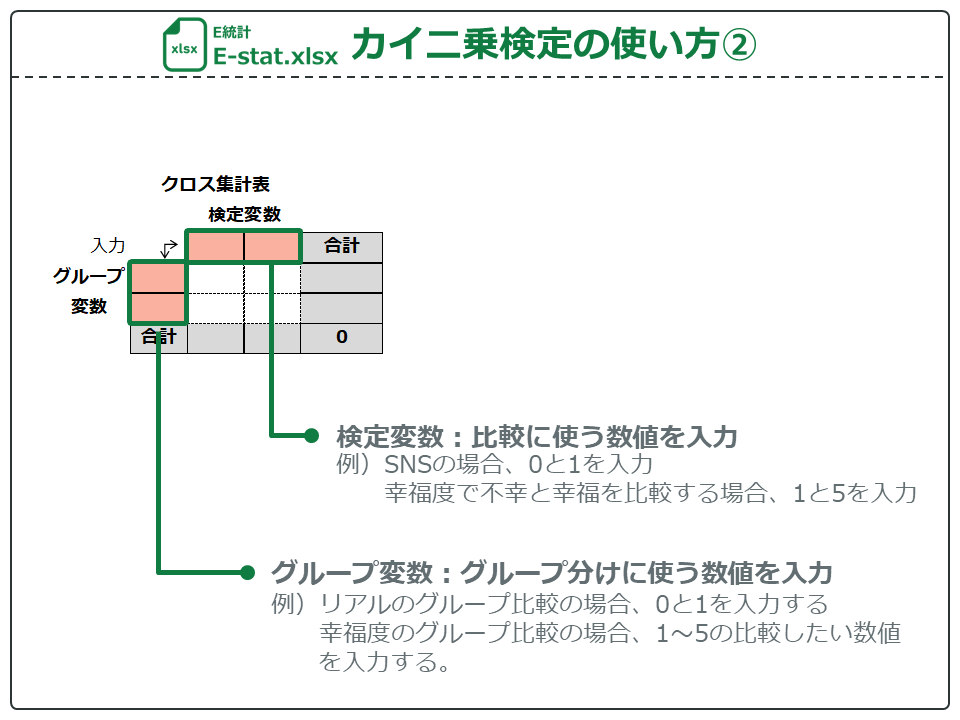
続いて、クロス集計表を作成します。
グループ変数にはグループ変数に入力した値から、どの値をグループに使うか入力します。「リアル」の場合、0と1を入力します。また、「幸福度」のように複数の値がある場合、比較したいグループの値を入力します。E統計では2つまでしかグループをクロス集計表に入力できません(2×2のクロス集計表しか計算できない)。
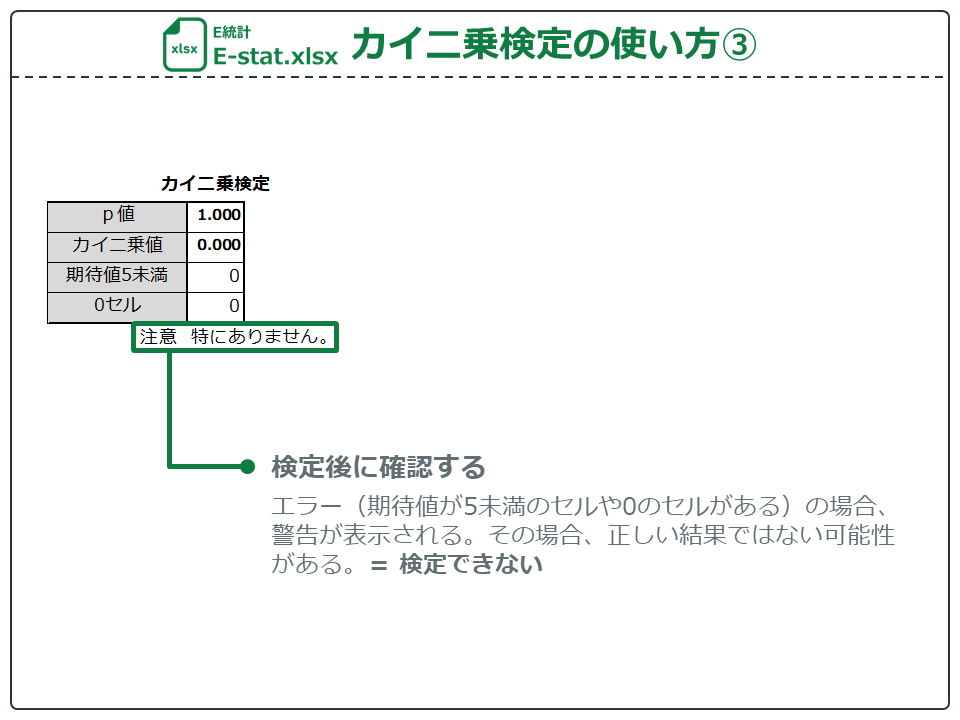
データの入力後、検定結果が出ますが、カイ二乗検定の表を確認してください。
エラー(期待値が5未満のセルや0のセルがある)の場合、警告が表示されます。その場合、正しい結果ではない可能性があります(= 検定できない)。
エラーの場合はFisherの正確検定を行う必要がありますが、E統計では対応していません。n数が少ないとエラーが負いやすいです。

E統計にデータをコピペするときに、値貼り付けを行うと、書式を崩すことなく貼り付けることができます。
もし、書式を崩してしまったり、間違えて変なところを消したり編集してしまった場合は、また新しいファイルをダウンロードしてください。これが一番確実ですね。

それでは、リア充と非リア充のSNS利用者の割合の差を検定していましょう!「対応なしデータ」から上記の手順で「E統計」に数値をコピペしてみましょう!
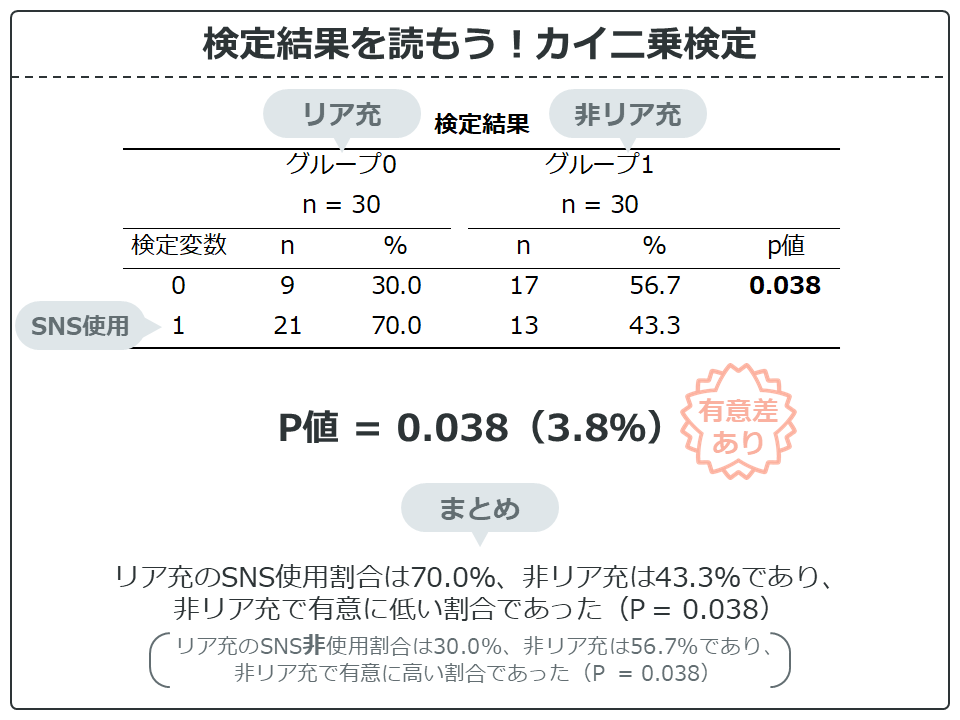
それでは結果を見てみましょう。グループ0はリア充、グループ1は非リア充ですね。
検定変数は、割合を求めた変数の値が表示されています。「SNS」の場合「1」の行はSNSの使用の該当者(n)と割合(%)を示しています。
リア充と非リア充のSNS使用割合の差は26.7%で、P値は0.038(3.8%)と有意水準0.05(5%)を下回っているので、有意差ありと判断できます。
論文等では「リア充のSNS使用割合は70.0%、非リア充は43.3%であり、非リア充で有意に低い割合であった(P = 0.038)」と表現することができます。
また、使用と非使用は表裏一体なので「リア充のSNS非使用割合は30.0%、非リア充は56.7%であり、非リア充で有意に高い割合であった(P = 0.038)」とも表記できます。この場合のP値は当然、同じ値になります。
さらに挑戦してみよう!カイ二乗検定
さて、もう少し練習してみたいという人は、下記からファイルをダウンロードしてください(ほか記事のE統計練習用ファイルと同じです)
使用するデータセットは同じです。